

What do you with a biologist who isn’t great with living things? In the lab, I tended to kill what needed to stay alive and cultivate contaminating microbes in places that needed to be sterile. Fortunately, I have a knack for getting computers to do what I want. And since evolution has an exploration-with-feedback problem-solving method at its core, it adapts well to computers. Computer scientists, engineers, designers and even artists and musicians have employed problem-solving techniques inspired by biological evolution to answer a variety of questions. But as a biologist, I’m more interested in studying evolution itself rather than using it as a tool to solve some other problem. So I find myself drawn more to artificial life simulations. But what to simulate?
My favorite superheroes are the X-Men, characters with superpowers through genetic mutations. Evolution is a frequent (if sometimes awkwardly handled) topic in X-Men stories, so using X-Men to study evolution is a natural fit. The X-Men also have a training facility where they learn how to work together as a team and solve problems. So what if they solved those problems in the evolutionary way? That’s the inspiration for the simulation I’ve been developing. Now, even though there are fair use exceptions for education, it’s probably not advisable to actually use the X-Men names or concepts, and not everyone is as enthusiastic for comic books as I am. Fortunately, the setup I have in mind is fairly common; the characters could equally be adventurers on a dungeon crawl or players trying to solve an escape room. Whatever the storytelling setting, the actual scenario involves one or more players in a room with obstacles or adversaries or puzzles that have to be overcome so they can exit. Instead of having humans control their actions like in a video game, the players’ actions are determined by a sequence of instructions encoded in a gene.
Let’s get a little more specific and put a player in a room with four opponents. Everyone has a laser gun. The player earns points for zapping their opponents and loses points for getting zapped. In order to clear the room, the player has to zap each opponent four times. At any given moment, the player can either move or fire their laser gun. They move up, down, left or right, or they can fire in one of those directions. So at each moment, they have to choose 1 of 8 options. A gene with a sequence of instructions thus needs to specify a series of these choices. For example, a gene might read “Move Left – Fire Up – Move Left – Move Down – Fire Right.” The simulation program will read those instructions and have the player act accordingly until the room’s goal is satisfied or the gene runs out of instructions.
We could (and hopefully will) extend this simulation to all kinds of tasks for our player(s). We could require them to rescue civilians, or find pieces to assemble into a gadget, or work out the numbers for a code that opens a lock, or navigate a maze. We could make a mixture of these challenges, assign different points to each, and see how many points could be accumulated. We just need to be able to program relevant actions and choose a way to encode them. And if it seems like cheating to program in actions like moving or firing a laser gun, consider that chemistry and physics provide amino acids with built-in activities. We don’t need to have the simulation evolve everything from “scratch” (whatever that might even mean) to have it be useful for studying evolution generally.

So now we have a way of representing a particular solution to our room challenge. For evolution, we still need a way to explore–mutation–and a way to provide feedback–selection. We’ll go through multiple generations, copying genes from one generation to the next and introducing mutations along the way. We can scan along a gene and copy instructions verbatim, but every once in a while change an action from ‘Move’ to ‘Fire’ or vice-versa, or change a direction to one of the other three. Over time, these mutations or variations will allow our players to explore the room we’ve built and also the abstract space of possible solutions.
For feedback, we already described a way to give each player a score. So we take a player with a gene, put them in the room, and see what score they get using that gene. Then we copy that gene with mutations and have a new player use that mutated gene and see what score they get. If the new score is the same or higher, we keep the new gene. If the new score is lower, we go back to the old gene. Then we repeat the mutate-and-score cycle with whichever gene we kept until either the player achieves the highest possible score or we’ve gone through as many iterations as we are willing to compute.
What happens when we do that? Well, you can see an example in the animations in this post. The first one at the top shows a player following a gene generated at random. They wander around, get zapped a few times, and don’t achieve the goal. The second animation shows a player following a gene generated via evolution from a random start point. There is still a fair amount of wandering, but ultimately the goal is achieved and the player can exit (note that the animation loops). Now, maybe I just got lucky with this test, or maybe I picked the best example to show you. To be more scientific, I ran the same experiment 256 times for 8,192 generations. Below, you can see the fitness at each generation averaged over all the trials. The average fitness (yellow line, lower right) increases quickly then levels off not quite at the maximum because some trials don’t get all the way there but most do.
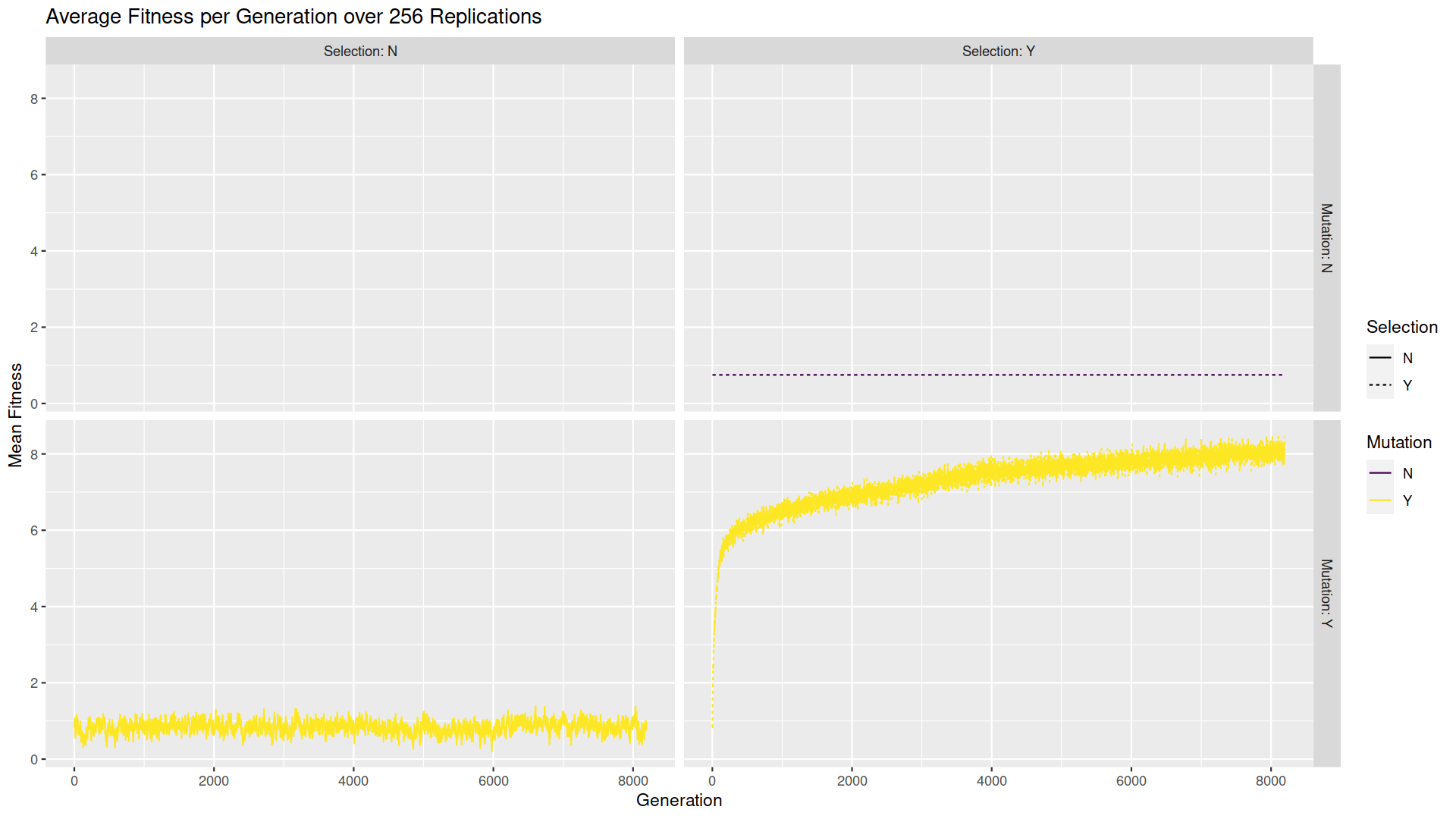
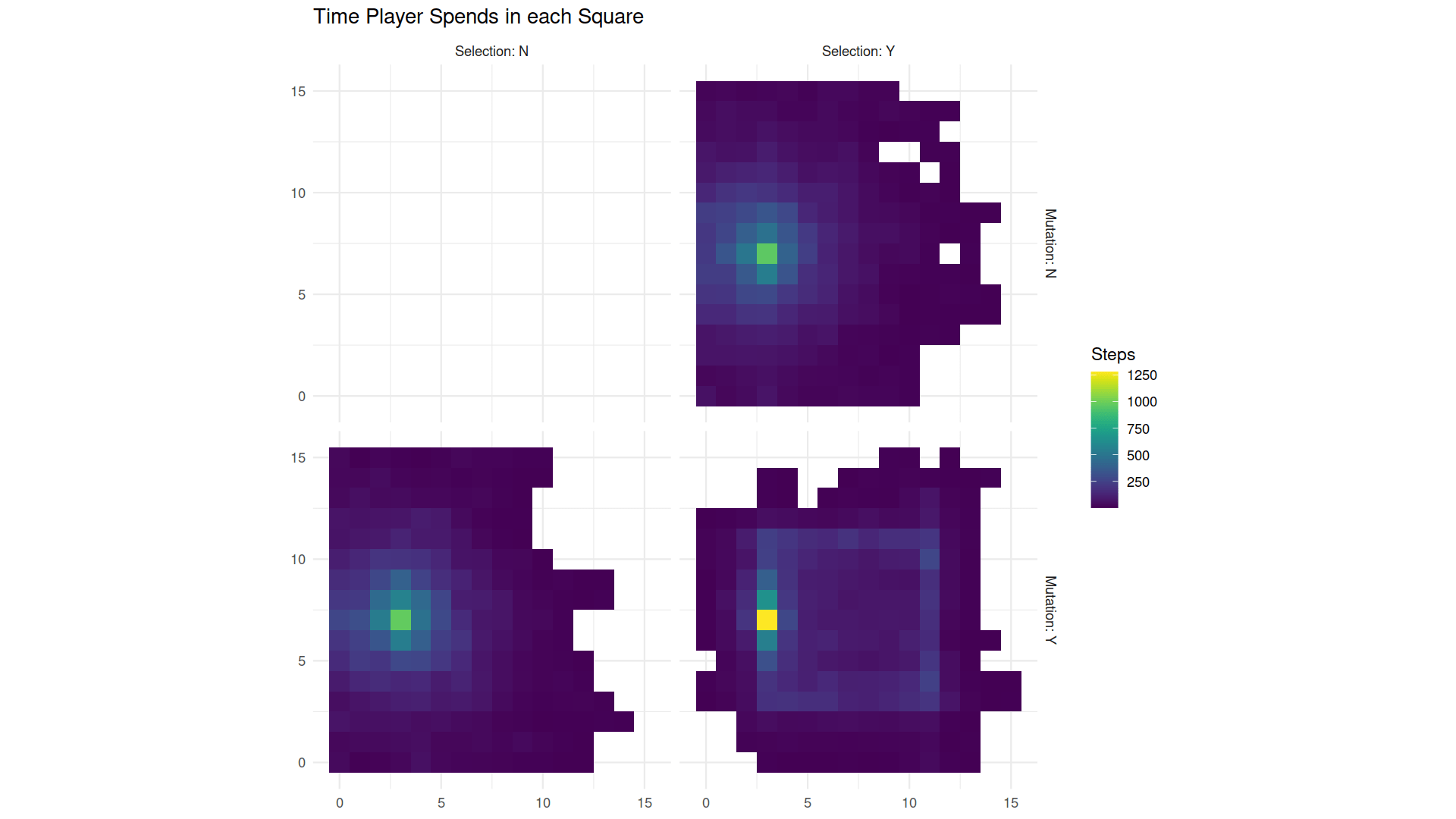
I also repeated the experiment twice, once leaving out the exploration/mutation step (upper right) and once leaving out the feedback/selection step (lower left). In both cases, the average score never gets any higher over time. Some changes over time in biological diversity can occur just from selection or just from mutation, but a full accounting of biology requires both. In our simulation, problem solving only occurs with both. The chart below shows another way to visualize this. Here, each square represents a position in the room and the color indicates how much time the player spends in each location. With just mutation or just selection, the player spends a decreasing amount of time in each square as they get further from the start point (bright yellow), and the player never gets all the way across the room. With both mutation and selection, the player can traverse the whole room and spends more time in certain squares–the ones from which the player can zap an opponent.
Now that we’ve seen some of the basics of the simulation and how evolution impacts the behavior of the player, here’s a question to think about for next week. What would change if the player had to get next to each opponent and tag them instead of zapping them with a laser? Feel free to share your hypothesis and your reasoning in the comments below.
Andy has worn many hats in his life. He knows this is a dreadfully clichéd notion, but since it is also literally true he uses it anyway. Among his current metaphorical hats: husband of one wife, father of two teenagers, reader of science fiction and science fact, enthusiast of contemporary symphonic music, and chief science officer. Previous metaphorical hats include: comp bio postdoc, molecular biology grad student, InterVarsity chapter president (that one came with a literal hat), music store clerk, house painter, and mosquito trapper. Among his more unique literal hats: British bobby, captain’s hats (of varying levels of authenticity) of several specific vessels, a deerstalker from 221B Baker St, and a railroad engineer’s cap. His monthly Science in Review is drawn from his weekly Science Corner posts — Wednesdays, 8am (Eastern) on the Emerging Scholars Network Blog. His book Faith across the Multiverse is available from Hendrickson.
Have you seen Mohamed Noor’s lectures/writings on genetics and evolution using Star Trek?
https://press.princeton.edu/books/hardcover/9780691177410/live-long-and-evolve
No, but now I’m intrigued!
I did hear a lecture once on the genetics of wizarding in Harry Potter. It was given by Peter Blier, a pediatrician at UMass. I didn’t find anything written by him, but a quick Google indicates lots of folks have used the wizarding trait to illustrate inheritance principles.