

While I assemble responses to the most pressing science & faith questions, I’d like to return to our exploration of evolution, starting with one of the evidently less pressing question. Previously, I introduced you to the Quandary Den, a simulation of a simple game that I paired with an evolutionary algorithm. The goal was to give you some hands-on experience with evolution and the use of simulation in experiments–and hopefully have some fun too. As I was working through responding to the eliminated science & faith questions, I realized I had also illustrated the answer to one of them, about the relationship between information and evolution.
I was actually a little surprised that question was eliminated so quickly. In some venues, the issue of where information comes from in biology comes up regularly. But I guess this isn’t one of those venues. Nevertheless, I think it’s a useful topic to address if we’re attempting a comprehensive look at evolutionary biology. Let’s start by getting clear on what information is and how it relates to to biology.
Discussing information usually starts with the formalism developed by Claude Shannon, a mathematician who defined entropy as a measurement to quantify information. More specifically, entropy represents the information capacity of a message source or channel. The basic unit of information entropy is the bit. To communicate the answer to one either/or question requires one bit. So a source measuring one bit of entropy can send two different messages, each representing one of the two possible answers. The higher the entropy of a source or channel, the more distinct messages it can send or carry. Thus more questions can be answered by a single message, or alternatively a more detailed answer to a more complex question can be given. When a website advertises 128-bit encryption, what they mean is that you’d have to answer 128 either/or questions correctly in a row to break the encryption–not easy to do. Or for another example, when we say a picture is worth a thousand words, we can back that up with entropy; while the ratio may not be exactly 1000:1, it does take many more bits to send a message containing a picture than a message containing a word.
Some initial applications of the entropy metric were in telecommunications, such as working out how many telephone lines (message channels) are needed to handle the volume of calls. As digital computers became more widespread along with digital storage, the bit was also a convenient unit for measuring storage capacity. At the lowest hardware level, computers have numerous elements that can be in two different physical states. Each of those elements can represent an answer to one of our either/or questions, meaning each element can hold a one-bit message. Nowadays consumer computers have billions or even trillions of such elements, allowing them to store billions of one-bit messages or a smaller number of longer or more detailed messages, perhaps representing one of those 1,000-word pictures. Physically, the elements are the same regardless of whether you are storing vacation pictures or the latest sci-fi ebook. The storage device is indifferent to the content; some other software or hardware feature of the computer needs to have a way to encode and decode messages into a series of either/or options.
Now we can start to think about the biology side of the story. All living organisms consist of one or more cells, each of which contains one or more DNA molecules. (Viruses are debatably alive but not cellular and may contain RNA instead of DNA.) DNA molecules are long chains made by connecting modular components one to another. Those components are called nucleotides, and in terms of the chemistry of making those chains, the four nucleotide varieties are interchangeable. The four options are adenine, cytosine, guanine, and thymine. A DNA molecule can be guanine-adenine-thymine-thymine-adenine-cytosine-adenine, or cytosine-adenine-thymine, or any other ordering. These molecules can be billions of nucleotides long–but how many bits? The most efficient encoding uses just two bits per nucleotide. The first bit can indicate (adenine/guanine) or (cytosine/thymine), and the second bit can indicate adenine or guanine, or it can indicate cytosine or thymine, depending on the first bit. So the roughly 3 billion nucleotides of the human genome would require 6 billion bits to transmit or store.
With this two-bit scheme, we have a way of encoding DNA sequences into a format that computers can store and transmit, and a way to compare one DNA molecule to another as measured in bits. Notice that along the way, we have transitioned from thinking about how many distinct messages we can get from a source or channel to thinking about encoding and storing messages. The two are closely related, but there is some subtlety worth addressing when it comes to biology. Consider a substitution mutation, a change to a DNA molecule so that instead of having the sequence cytosine-adenine-thymine it has the sequence thymine-adenine-thymine. If we think of ‘life’ as a message source and DNA molecules as the individual messages, then a mutation like that could represent an increase in entropy if it created a new, distinct message we hadn’t seen before. Having seen it, we would update our tally of the number of distinct messages, which would update our estimate of the entropy of our source. But if we think of DNA as a storage medium akin to a hard drive, the cytosine->thymine mutation might seem more like an erasure (or partial erasure) of information. If you stored a message on your hard drive and then some of the elements got changed to the opposite physical state, you would not get back the same message when you tried to get it back out. So depending on whether we are thinking about the diversity of all messages or the storage of a particular message, we might have a different view of how mutations relate to information.
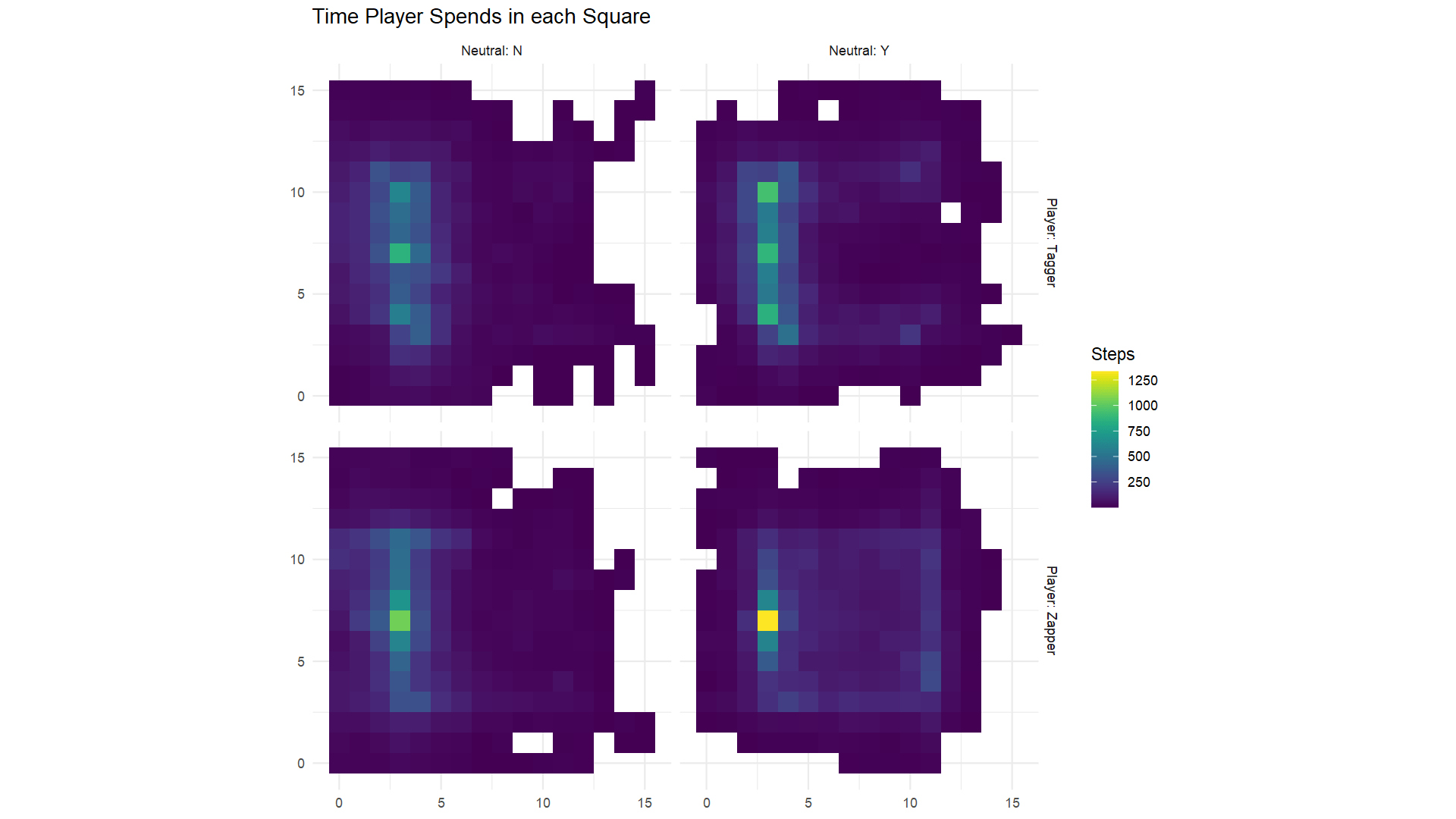
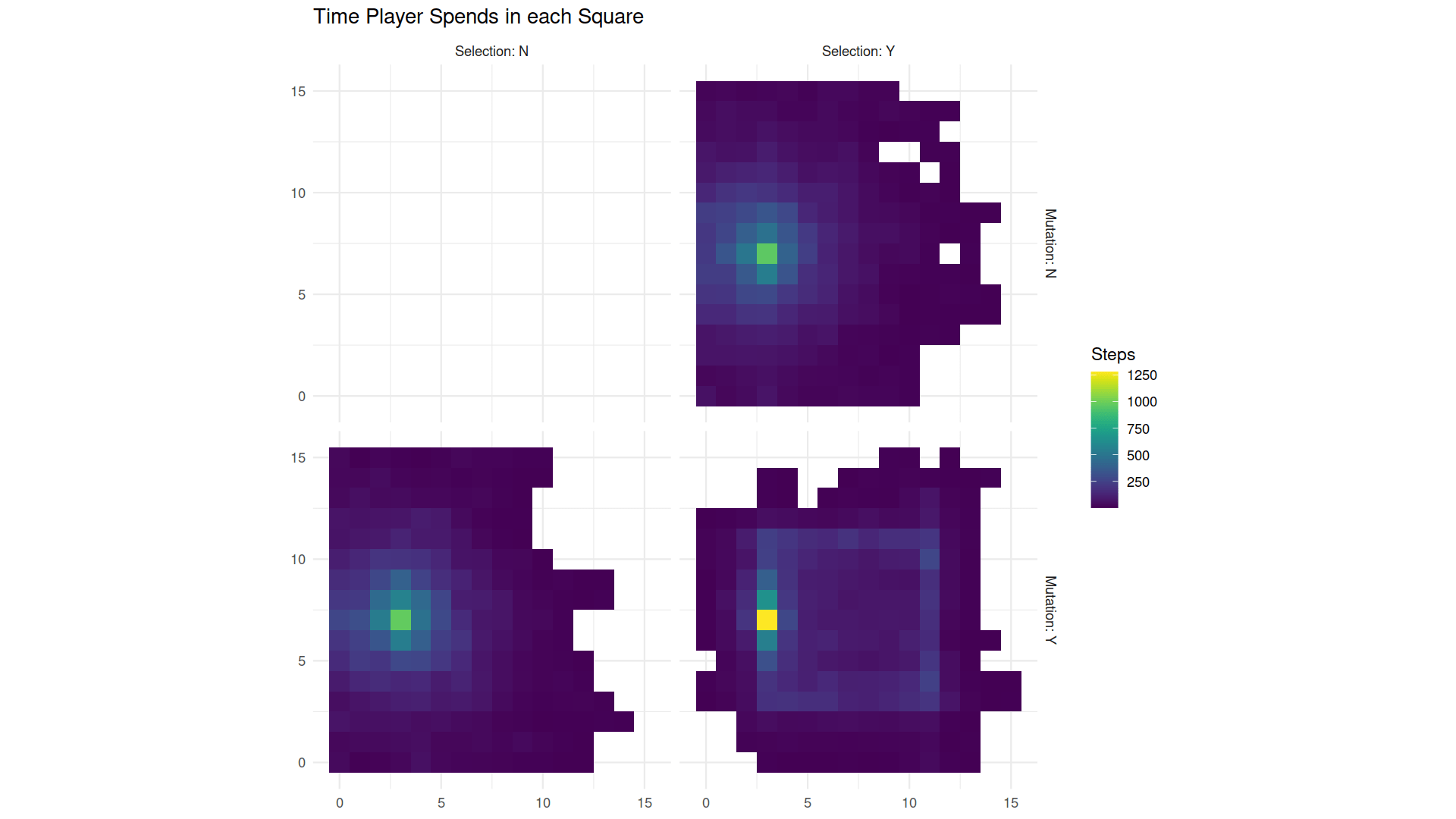
If we allow that information is stored in DNA, and if mutations erase bits of that stored information, how does information get there in the first place? In terms of evolutionary processes, selection can lead to stored information. Basically, selection eliminates all the variations that are not the information relevant to reproduction, while information that is relevant to reproduction persists and can thus be considered stored. And in our Quandary Den simulations, we saw an example of this. In our first set of experiments, we saw where the player spends time if their moves are random–basically, they spread out equally in all directions from the starting point, as demonstrated in the first set of charts above. When we later looked at neutral mutations, after selection we saw that taggers spend more time in squares adjacent to the robots than in other squares, as in the second set of charts. From this, we get information about where the robots are, stored in the movements of the players which are in turn stored in their genome by evolution.
Readers interested in another of our questions–What would the discovery of extraterrestrial life mean for Christianity?–may be interested in an upcoming webinar on the possibility of intelligent life elsewhere in the cosmos and the ramifications. I’m not particularly familiar with the speakers’ perspectives on the topic, but I’d expect an informative discussion.
Andy has worn many hats in his life. He knows this is a dreadfully clichéd notion, but since it is also literally true he uses it anyway. Among his current metaphorical hats: husband of one wife, father of two teenagers, reader of science fiction and science fact, enthusiast of contemporary symphonic music, and chief science officer. Previous metaphorical hats include: comp bio postdoc, molecular biology grad student, InterVarsity chapter president (that one came with a literal hat), music store clerk, house painter, and mosquito trapper. Among his more unique literal hats: British bobby, captain’s hats (of varying levels of authenticity) of several specific vessels, a deerstalker from 221B Baker St, and a railroad engineer’s cap. His monthly Science in Review is drawn from his weekly Science Corner posts — Wednesdays, 8am (Eastern) on the Emerging Scholars Network Blog. His book Faith across the Multiverse is available from Hendrickson.
Leave a Reply