

For the past couple of weeks, we’ve been looking at password puzzles as models for evolutionary biology. This week I said we would stay with language as an inspiration for models but try to widen the scope. As it turns out, the programming didn’t go exactly as I had intended. I still have some variations for us to look at, but they aren’t as big of a departure. Still, one of my goals for this series was to give you a glimpse of science in real-time, and having to adjust plans based on what is possible is all part of how science gets done. So we’ll push on.
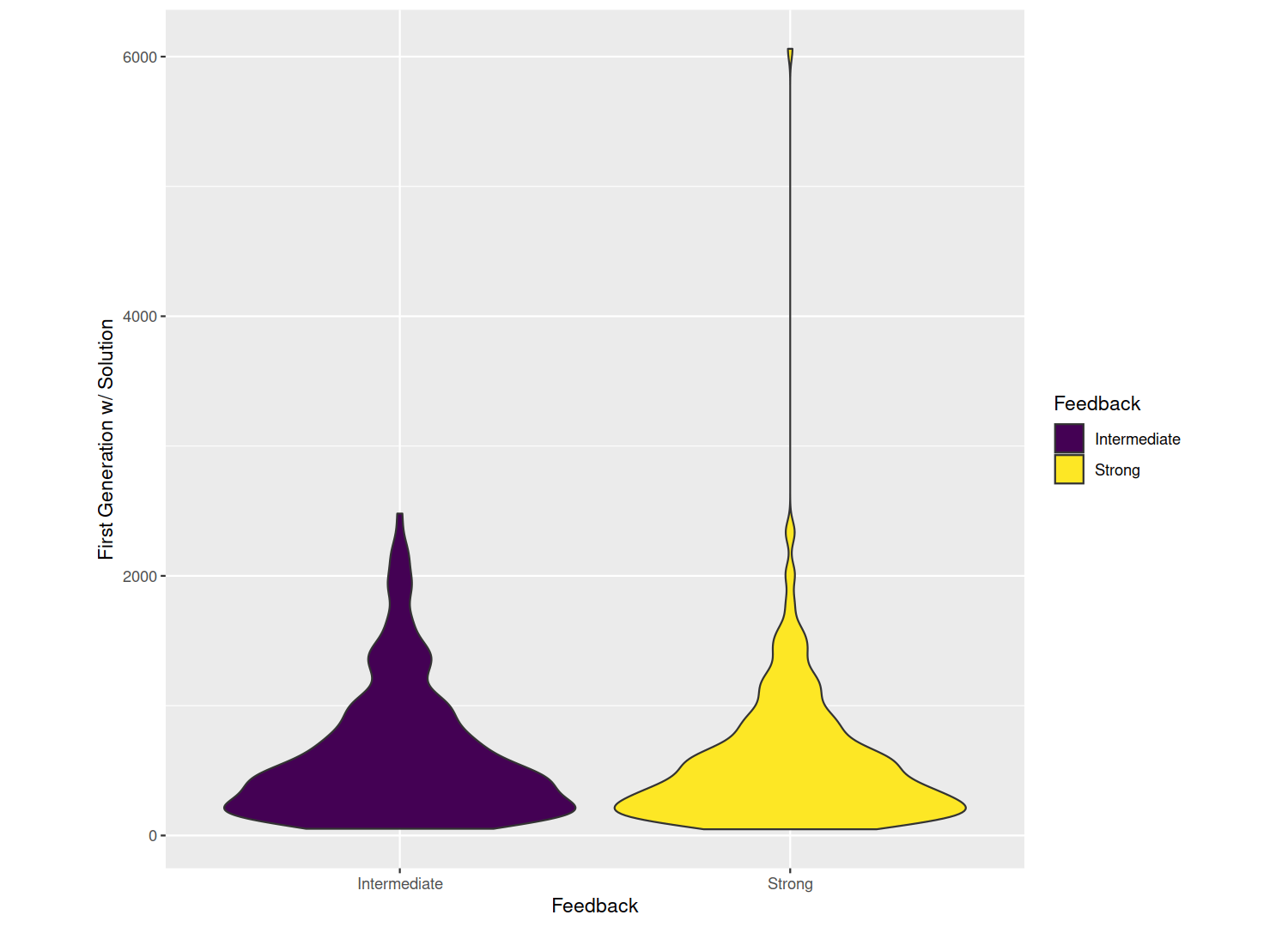
Two weeks ago I gave you some puzzles to try with varying levels of feedback, and last week we discussed how well those stand in as models of evolutionary biology. Now, let’s take a look at how an evolutionary algorithm does in those scenarios. The chart below shows on average how many generations of evolution it took to solve the puzzle with the given amount of feedback. Results for weak feedback (just yes/no was a guess the password) are not shown because the problem is essentially unsolvable; in over a quarter million generations no solution was reached in any of the 1,024 repetitions. With intermediate feedback (how many correct letters, purple/left) and strong feedback (correct letters are ‘locked in’, yellow/right), the evolutionary algorithm can solve the puzzle. But there is no difference in how long it takes (the strong feedback distribution goes higher, but that’s just one repetition; in general the two distributions are equivalent). That’s probably different than your results, because you can use different algorithms or problem solving strategies besides evolution that are better matched to the scenario. For example, last week I told you how to solve the strong feedback puzzle in no more than 26 tries (or generations), but that strategy won’t work for the intermediate feedback puzzle.
Given those results, we might ask if there are any scenarios in which an evolutionary algorithm can do better than it did in the intermediate or strong feedback scenarios. And the answer is ‘yes’. Here’s one version you can try; it is another version of the weak feedback scenario but I think you’ll do better now than two weeks ago:
And in the chart below you can see how an evolutionary algorithm does (green/center-right). Even with weak feedback, now the same evolutionary algorithm can find a solution, sometimes quite quickly. So what changed? Well, instead of a specific password, now the puzzle will accept any valid English word that is six letters long. That’s still not automatic; there are more combinations of six letters that are nonsense (at least in English) than are valid words. But it is an easier task. That would be silly for an actual password, but biologically it is not as far removed from reality. In some cases, a new gene doesn’t need to have one specific function to be useful, it just needs to do something. Sure, there are specific needs, like when the immune system is trying to evolve antibodies to a specific pathogen, but even then there is more than one viable solution. Evolutionary history contains plenty of both situations–environmental changes requiring more targeted responses and multiplicities of available niches, any one of which could be explored.
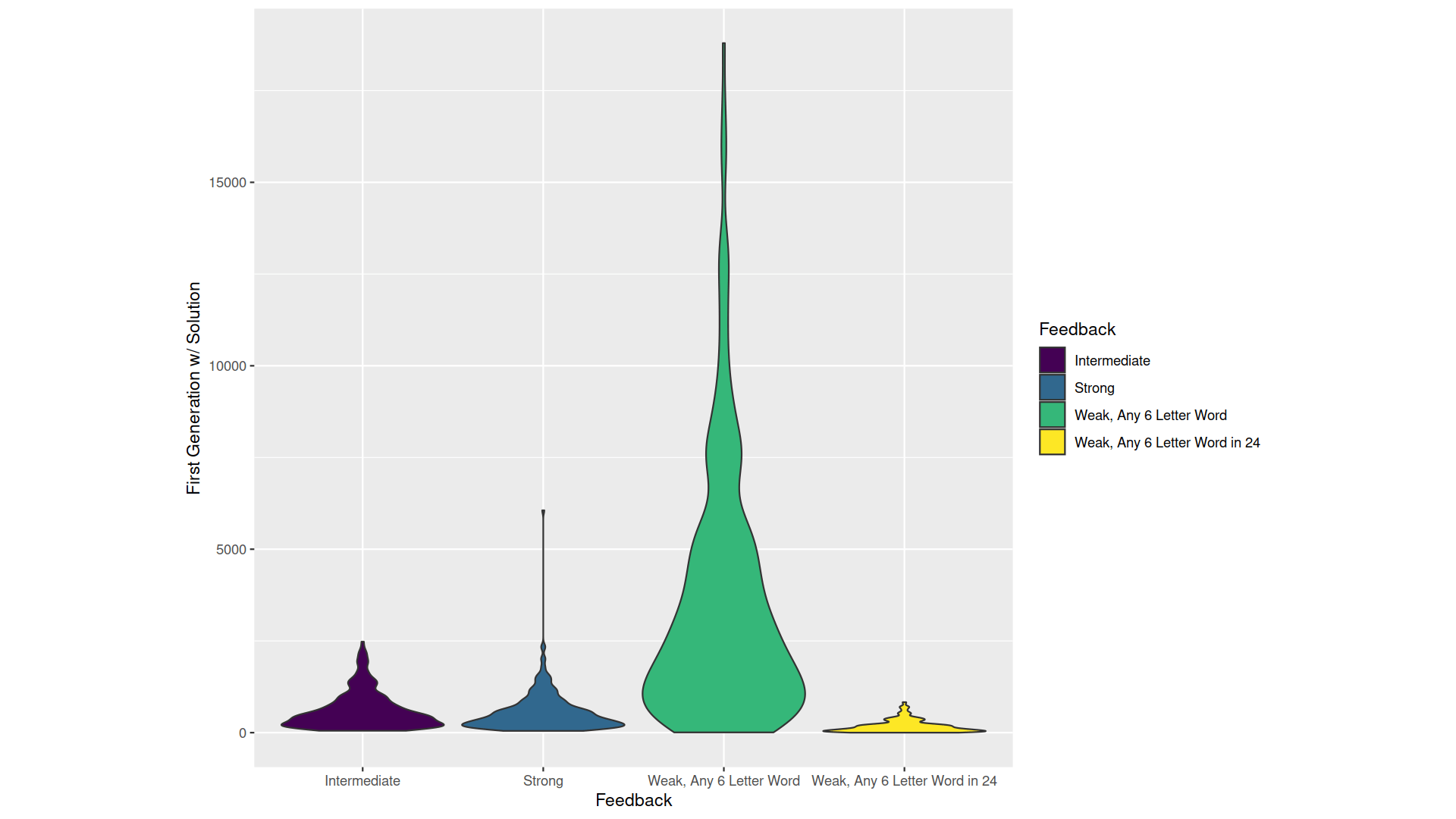
We can tweak the scenario even further and see that a solution can be found even faster if the algorithm gets 24 letters to work with and just needs a six-letter word somewhere in that stretch (yellow/right). This is even more comparable to biology because new genes do not have to arise in a particular place in the genome. Or another way to think about that flexibility of solution is that not every part of a gene has to have a specific sequence to carry out a particular function; there are typically some critical regions where only one or a few sequences will work and other regions that are much less constrained. That’s a little trickier to represent in our password puzzle game. I could certainly program it, but the instructions and the results might be more confusing.
Here’s one more version that you can try interactively. Now you get intermediate feedback, that is you get to know how many letters were correct.
As you might have suspected, this version accepts any valid English word as well. I couldn’t repeat this simulation quite as many times in the allotted time because of the computational cost, but you can see the results for 128 repetitions below (dark blue/left of center) and observe that performance is even faster. This would correspond to a biological scenario where multiple niches are open to be explored, and the relevant biochemistry or physiology has varying degrees of efficacy.
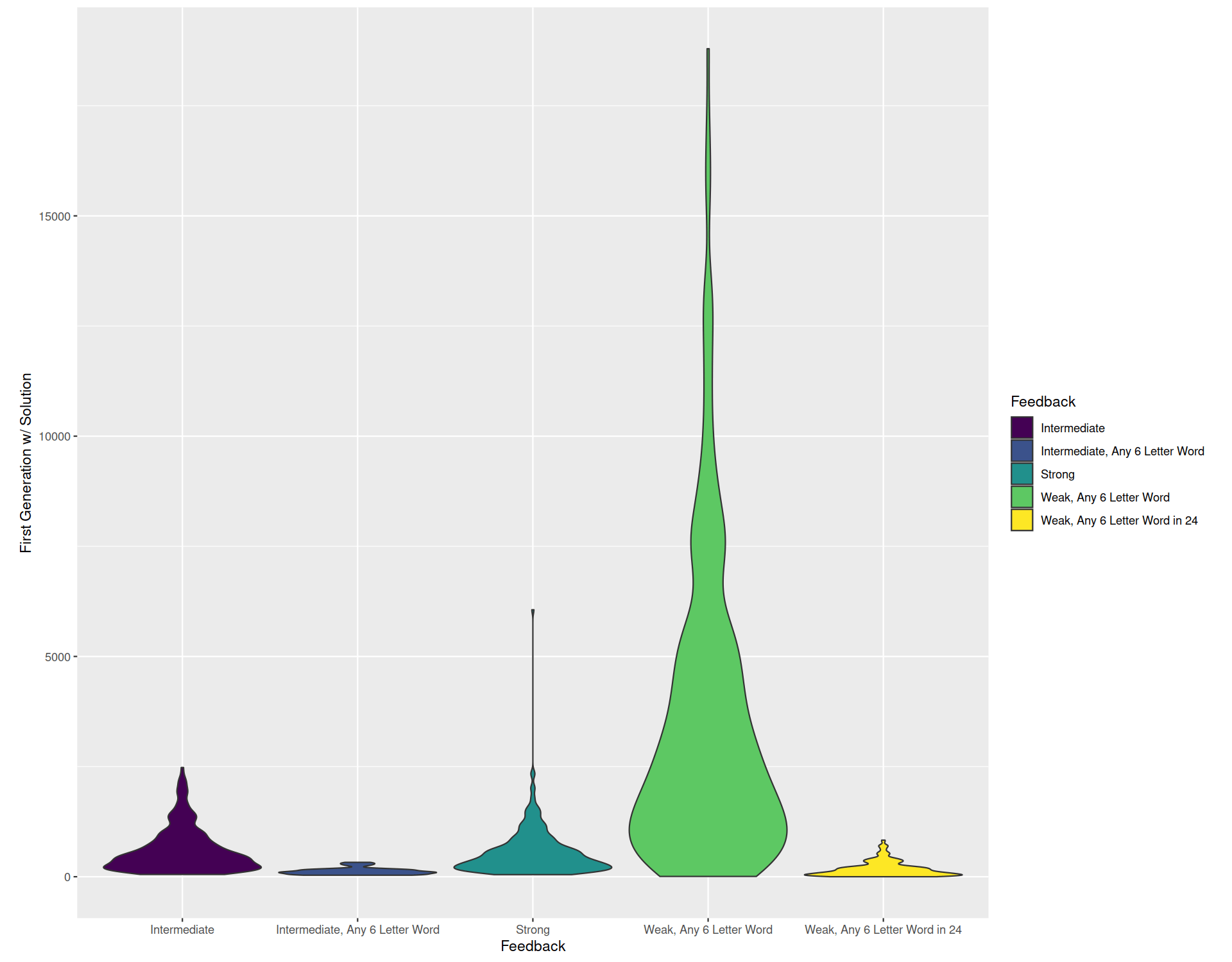
I thought this was interesting as well because it touches on another aspect of modeling. Not only can models vary in how well they match what you are trying to model (as discussed last week), they can also vary in how easy they are to implement and how appealing they are to work with. That can introduce bias into our modeling exercises. In and of itself, that bias isn’t a bad thing, but it’s something to be consider. Just because the most appealing or easiest models don’t represent what we wish to understand perfectly doesn’t mean that there isn’t a useful model out there that requires a little more work or imagination to find.
Andy has worn many hats in his life. He knows this is a dreadfully clichéd notion, but since it is also literally true he uses it anyway. Among his current metaphorical hats: husband of one wife, father of two teenagers, reader of science fiction and science fact, enthusiast of contemporary symphonic music, and chief science officer. Previous metaphorical hats include: comp bio postdoc, molecular biology grad student, InterVarsity chapter president (that one came with a literal hat), music store clerk, house painter, and mosquito trapper. Among his more unique literal hats: British bobby, captain’s hats (of varying levels of authenticity) of several specific vessels, a deerstalker from 221B Baker St, and a railroad engineer’s cap. His monthly Science in Review is drawn from his weekly Science Corner posts — Wednesdays, 8am (Eastern) on the Emerging Scholars Network Blog. His book Faith across the Multiverse is available from Hendrickson.
Leave a Reply